Le centre de calcul du LMM est
équipé depuis septembre 2006 d'un nouveau
cluster dédié au calcul parallèle
sous MPI.
Ce cluster est constitué de 20 noeuds bi-Opteron
265 Dual
Core, soit l'équivalent de 80 processeurs et une puissance
de
crête (théorique) de 288 Gigaflops, chaque noeud est pourvu de 8 Go de
Mémoire.
Le système installé est la
version 4.2 de Rocks Cluster http://www.rocksclusters.org
qui repose sur la distribution Linux Centos 4.3
x86_64 http://www.centos.org
. Pour la gestion des jobs
parallèles on a choisi d'utiliser Sun
Grid Engine (SGE version 6.0 update 8).
Le choix des librairies MPI pour la configuration de l'environnement
parallèle de SGE est MPICH2
conforme au standard MPI-2 (inclus MPI-1), MPICH2 offre pour
la
gestion des processus le
choix
parmi 3 process managers (mpd par defaut, smpd, et gforker), les
librairies MPICH2 (mpich2-1.0.4p1) ont été
compilées avec l'option:
./configure
--prefix=/share/apps/mpich2_smpd --with-pm=smpd
--with-pmi=smpd
Comment
lancer un job parallèle
1/
Configurer son compte
Il faut d'abord créer un fichier hostfile
sur son compte contenant :
compute-0-0 cpu=4
compute-0-1 cpu=4
compute-0-2 cpu=4
compute-0-3 cpu=4
compute-1-0 cpu=4
compute-1-1 cpu=4
compute-1-2 cpu=4
compute-1-3 cpu=4
compute-1-4 cpu=4
compute-1-5 cpu=4
compute-1-6 cpu=4
compute-1-7 cpu=4
compute-2-0 cpu=4
compute-2-1 cpu=4
compute-2-2 cpu=4
compute-2-3 cpu=4
compute-2-4 cpu=4
compute-2-5 cpu=4
compute-2-6 cpu=4
compute-2-7 cpu=4
babbage.local cpu=0
Ensuite il faut créer un fichier .smpd avec un éditeur de
votre choix, par exemple vi, vérifiez que les droits sont bien rw juste
pour vous, le fichier contient seulement "phrase=votre_nom" :
[my_login@babbage
~]$ more .smpd
phrase=my_name
[my_login@babbage ~]$ ls -l .smpd
-rw------- 1 my_name my_name 14 Dec 11 12:10 .smpd
[my_login@babbage ~]$
Si les droits ne sont pas bons, changez les avec la commande chmod 600 .smpd
sinon vous ne pourrez pas démarrer vos jobs.
Une fois ce fichier créé,
on ne s'occupe plus des daemons smpd, ceux-ci sont directement
gérés par les scripts de démarrage de Sun Grid
Engine, via la commande qsub. Vérifiez régulièrement
avant de lancer des calculs le contenu de ce fichier, quand un calcul
se termine normalement le fichier contient seulement la ligne
"phrase=votre_nom". Au cours du calcul Sun Grid
Engine ajoute dynamiquement le nom des noeuds utilisés pour le calcul
et les enlève à la fin du calcul, si ce n'est le cas,
rééditez le fichier et verifiez les droits comme
indiqué ci-dessus.
Vérifiez le contenu des
variables $PATH
et $LD_LIBRARY_PATH par défaut et modifiez votre
.bash_profile selon ce que vous voulez faire.
[my_login@babbage ~]$ echo
$PATH
/opt/gridengine/bin/lx26-amd64:/usr/kerberos/bin:/usr/java/jdk1.5.0_05/bin:
/opt/intel/itc60/bin:/opt/intel/ita60/bin:/opt/intel/fce/9.0/bin:/opt/intel/idbe/9.0/bin:/opt/intel/cce/9.0/bin:
/usr/local/bin:/bin:/usr/bin:/usr/X11R6/bin:/opt/apache-ant/bin:/opt/ganglia/bin:
/share/apps/mpich2_smpd/bin:/opt/rocks/bin:/opt/rocks/sbin:
/home/my_login/bin
[my_login@babbage ~]$ echo $LD_LIBRARY_PATH
/opt/gridengine/lib/lx26-amd64:
/opt/intel/cmkl/8.0/lib/em64t:/opt/intel/itc60/slib:/opt/intel/ipp41/em64t/sharedlib:/opt/intel/fce/9.0/lib:/opt/intel/cce/9.0/lib:
/share/apps/mpich2_smpd/lib
[my_login@babbage ~]$
Par exemple, pour utiliser
la version préinstallée de Gerris
vous pouvez ajouter /share/apps/gerris/bin
dans votre PATH.
[my_login@babbage
~]$ which mpiexec
/share/apps/mpich2_smpd/bin/mpiexec
[my_login@babbage ~]$ which mpicc
/share/apps/mpich2_smpd/bin/mpicc
[my_login@babbage ~]$ mpicc -show
gcc
-I/share/apps/mpich2_smpd/include -L/share/apps/mpich2_smpd/lib -lmpich
-lpthread -lrt -ldl -lssl -luuid -lpthread -lrt -ldl
[my_login@babbage ~]$
2/
Compiler un code parallèle sur le cluster
Pour compiler en C, on utilise la commande mpicc de MPICH2.
Pour compiler en C++, on utilise la commande mpicxx de MPICH2.
Pour compiler en fortran 77, on utilise la commande mpif77 de MPICH2.
Pour compiler en fortran 90, on utilise la commande mpif90 de MPICH2.
si par exemple on veut compiler en C le code Gerris avec les
librairies MPICH2 :
./configure
--prefix=/home/my_directory/local/gerris
--with-mpicc=/share/apps/mpich2_smpd/bin/mpicc
CPPFLAGS = -I/share/apps/mpich2_smpd/include
LDFLAGS = -L/share/apps/mpich2_smpd/lib
--disable-shared
3/
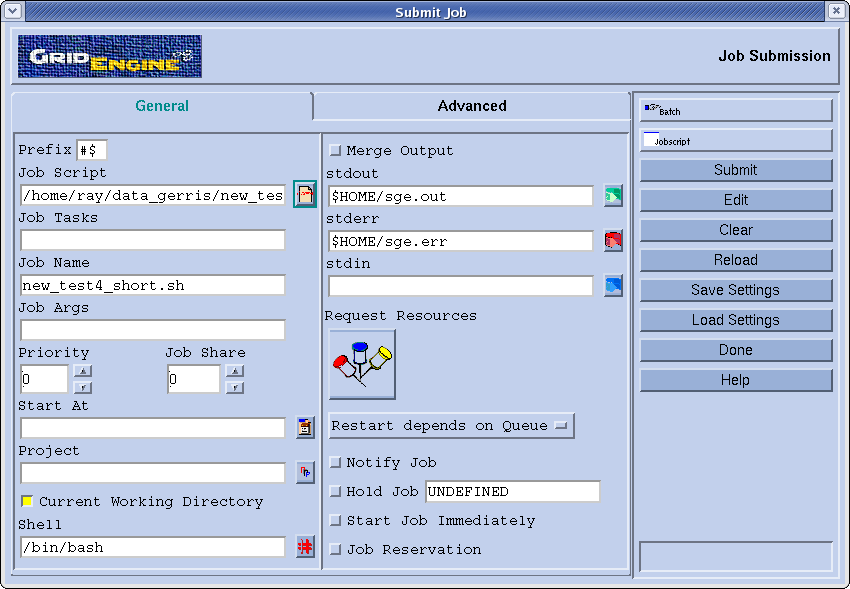
Ecrire son fichier de batch
Pour lancer un job parallèle sur le cluster vous devez impérativement
le lancer avec la commande qsub
( voir les man_pages
de SGE) et via un fichier de batch, par exemple :
qsub my_job.sh
Voici un exemple de batch pour lancer un calcul avec
Gerris2D ( test_gerris.sh)
:
#!/bin/bash
#$ -S /bin/bash
#$ -M my_login@mon_labo.jussieu.fr
#$ -m bea
#$ -o $HOME/sge.out
#$ -e $HOME/sge.err
#$ -cwd
#$ -v HOME
#$ -v LD_LIBRARY_PATH
#$ -v PE_HOSTFILE=$HOME/hostfile
# calcul parallele sur 4 processeurs
#$ -pe mpich2_smpd 4
MPI_DIR=/share/apps/mpich2_smpd
port=$((JOB_ID % 5000 + 20000))
$MPI_DIR/bin/mpiexec -n $NSLOTS -machinefile $TMPDIR/machines -port
$port /share/apps/gerris/bin/gerris2D $HOME/data_gerris/half4.gfs
Ce fichier de batch envoie un email lorsque le calcul commence (b pour begin),
fini (e pour end)
ou échoue pour une raison quelconque (a pour abort),
écris un fichier sge.err
très utile pour savoir pourquoi un job ne démarre pas, un fichier sge.out pour les
sorties standards, cherche les fichiers depuis le répertoire où qsub
est lancé (-cwd),
transmet les variables d'environnement $HOME
et $LD_LIBRARY_PATH
aux scripts de lancement de SGE.
les options suivantes sont obligatoires :
la variable $PE_HOSTFILE fournit
des informations sur les noeuds utilisables (nombre de processeurs par
noeud), les scripts de lancement de SGE sélectionnent ensuite
les noeuds
adéquates en fonction des options décrites plus bas et
génèrent un fichier temporaire $TMPDIR/machines.
#$ -pe mpich2_smpd 4 précise que l'on veut lancer le
calcul parallèle sur 4 processeurs en utilisant l'environnement
parallèle mpich2_smpd
de SGE, ce qui détermine les scripts de lancement du job par
SGE. le cluster est configuré pour lancer les jobs avec cet
environnement parallèle.
port=$((JOB_ID % 5000
+ 20000)) précise le numero de port qui sera utilisé par
les daemons smpd pour communiquer, ne pas changer cette option !
mpiexec
-n
( et pas -np) est la commande qui remplace mpirun dans MPICH2 et que
vous devez utiliser pour lancer vos jobs parallèles ( à
ne pas confondre avec le mpiexec de LAM-MPI), les variables $NSLOTS et
$TMPDIR sont fournies par les scripts de lancement de SGE.
4/
Où stocker ses données
Si vous avez des données de calcul volumineuses, vous devez les
écrire dans /home/data
et non dans votre répertoire perso. Vous disposez pour le moment
de 1 Teraoctet commun à tous les utilisateurs dans le
répertoire /home/data.
5/
Utiliser l'interface graphique de Sun Grid Engine : qmon
Vous pouvez soumettre des commandes et des jobs soit en ligne de
commande, pour cela lisez les man_pages
de SGE, soit via l'interface graphique de SGE :
qmon&
Vous pouvez aussi trouver la documentation de SGE ici
: Grid_Engine_6_user's_guide.pdf
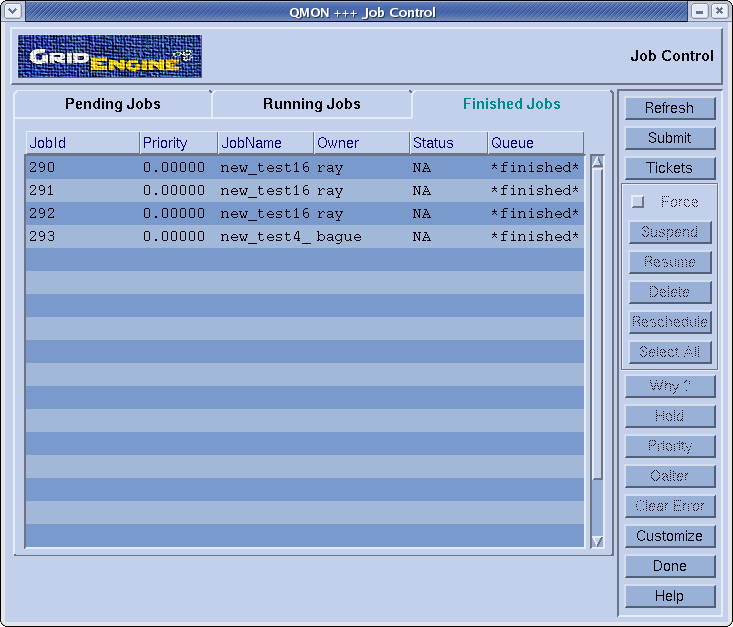
6/
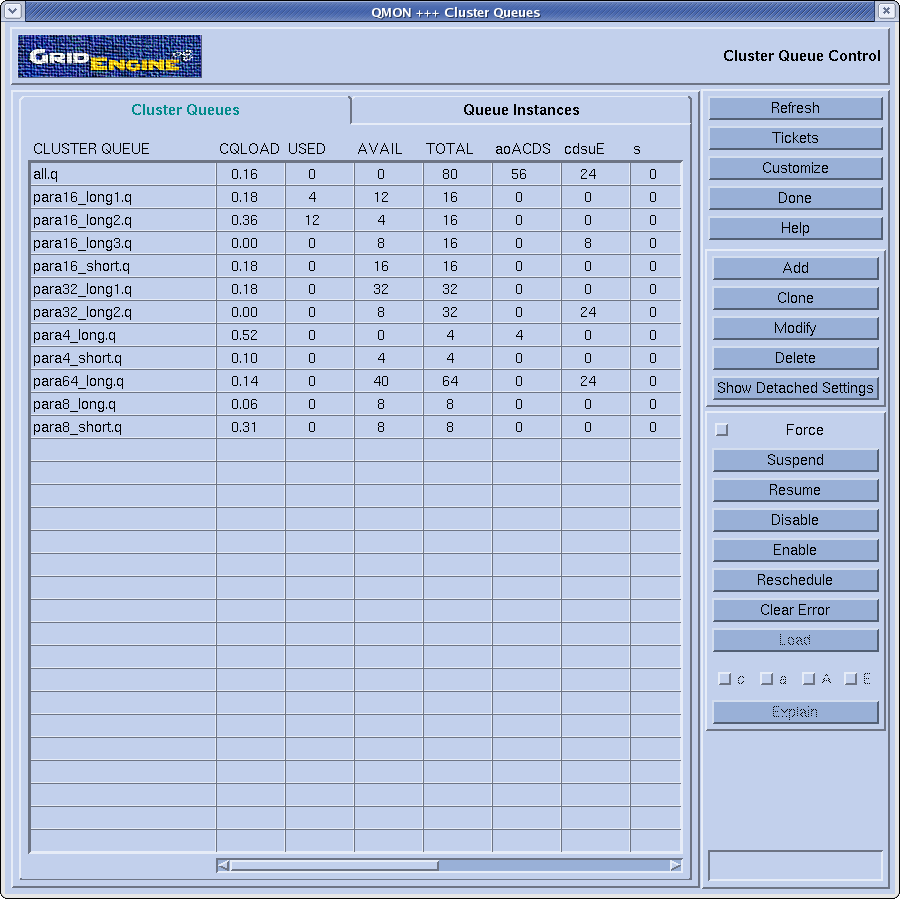
Structure du cluster pour la soumission des jobs -
Définition des queues
Le cluster comprend des queues superposées selon le schema
ci-dessous pour la soumission des jobs.
Sur les 4 premiers noeuds :
3 queues pour tester les jobs sur 4, 8, et 16 processeurs pendant 6
minutes maximum (para4_short, para8_short, para16_short).
3 queues pour lancer les jobs sur 4, 8, et 16 processeurs par tranche
de 12h de temps réel (para4_long, para8_long, para16_long1).
Sur les 16 autres noeuds :
1 queue pour lancer les jobs par tranche de 12h sur 64 processeurs
(para64_long)
2 queues pour lancer les jobs par tranche de 12h sur 32 processeurs
(para32_long1 et para32_long2)
2 queues supplémentaires pour lancer les jobs par tranche de 12h sur 16
processeurs (para16_long2 et para16_long3)
ce que l'on peut schematiser ainsi :
| para16_short
+ para16_long1 |
para64_long |
| para8_short |
para8_long |
para32_long1 |
para32_long2 |
| para4_short |
|
para4_long |
|
para16_long2 |
|
para16_long3 |
|
les priorités entre les queues se font ainsi, si une
queue dans le schéma est au-dessus d'une autre, alors elle est
prioritaire sauf pour les para4_short et para8_short qui peuvent
toujours démarrer. Une queue n'accepte qu'un seul job sauf si
celui-ci n'occupe pas les processeurs à 100%, les
critères s'appliquent en termes de charge des processeurs.
Pour pouvoir accéder aux différentes queues, il faut
utiliser les options suivantes dans son fichier de batch, d'abord
spécifier le nom de la queue via l'option :
#$ -l q=le_nom_de_la_queue
les noms possibles pour cette option sont para4_st, para8_st,
para16_st, para4_lg, para8_lg, para16_lg1, para16_lg2, para16_lg3,
para32_lg1, para32_lg2, para64, night80, et all.
pour les queues long (long=12h temps réel), il faut
ajouter l'option :
#$ -l h_rt_min=une
valeur plus grande que 360 (secondes !)
A titre d'essai, il existe deux queues supplémentaires, all.q et
night80_long.q, qui utilisent les 80 processeurs, all.q ne fonctionne
que le week-end pendant 48h max et n'a aucune priorité,
night80_long.q ne fonctionne qu'entre 18h et 6h du matin du lundi au
vendredi et est prioritaire sur toutes les paraxx_long, sauf
para4_long.q qui ne fonctionne qu'entre 6h et 18h.
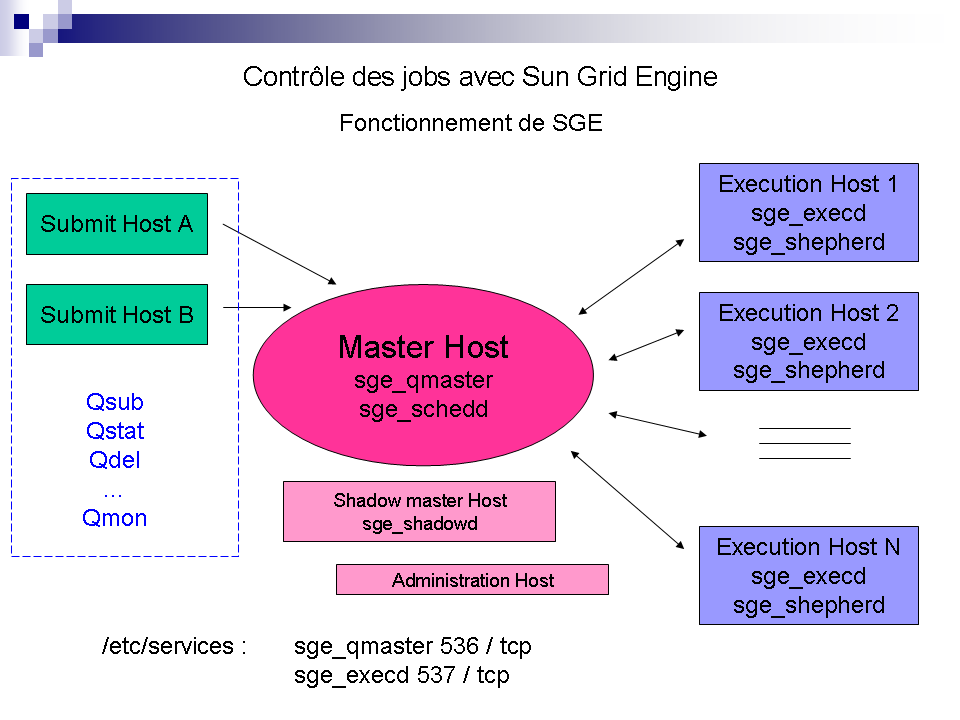
Comment
fonctionne Sun Grid Engine
1/ Schéma de fonctionnement
Le fonctionnement de Sun Grid Engine repose principalement sur les
daemons suivants :
-sur le master : sge_qmaster
et sge_schedd
-sur les noeuds de calcul : sge_execd
et sge_shepherd
Les demandes des client
(via qsub ou autre) sont gérées par qmaster et
schedd sur le frontal du cluster et ensuite transmises à execd
sur les noeuds de calcul, mais le daemon qui nous interesse le plus
et qui au final contrôle les jobs est,
comme son
nom l'indique, le daemon shepherd, lui même sous le
contrôle de execd.
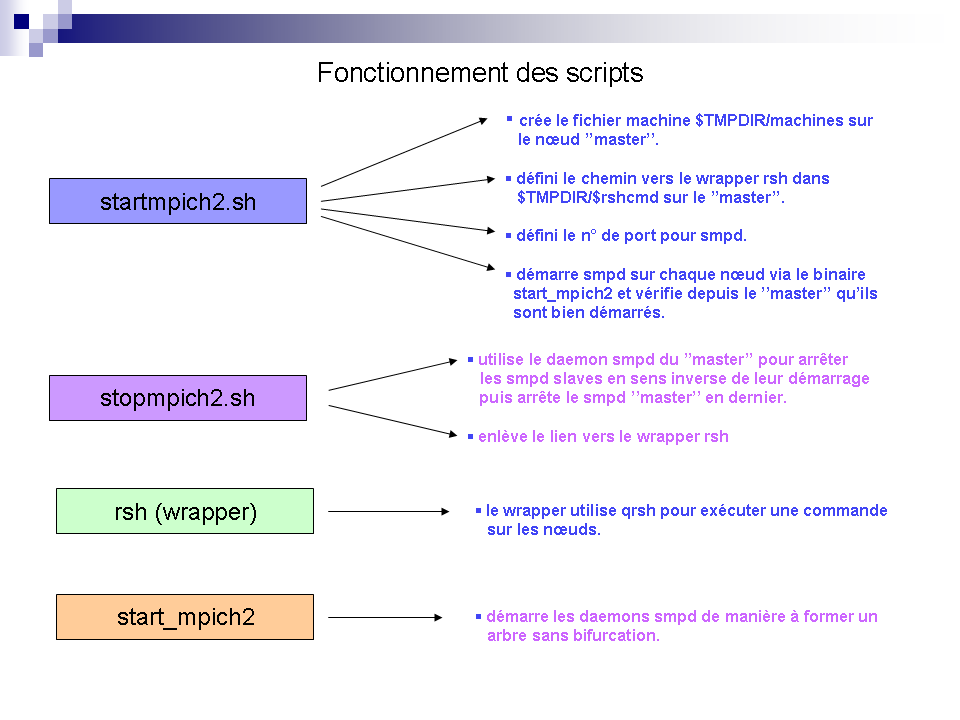
2/
Fonctionnement des scripts pour mpich2_smpd
Avant qu'un calcul
parallèle
puisse être lancé, il y a un certain nombre de
tâches préparatoires à effectuer, ce travail est
réalisé par les scripts de démarrage qui vont par
exemple démarrer les daemons smpd nécessaire pour les
communications entre les noeuds, c'est l'équivalent des
commandes "lamboot" ou "mpdboot" que vous tapez
généralement à la main, sauf qu'ici les scripts
vous garantissent un contrôle sûr des jobs et des daemons
smpd, si vous faites un
qdel
il ne restera ni jobs ni daemons smpd sur les noeuds, c'est ce qu'on
appelle "Tight Integration". Si vous voulez savoir ce que font
exactement ces scripts lisez les
Howtos
de Sun Grid Engine.
3/
SGE à la loupe !
Pour mieux comprendre voici quelques exemples ...
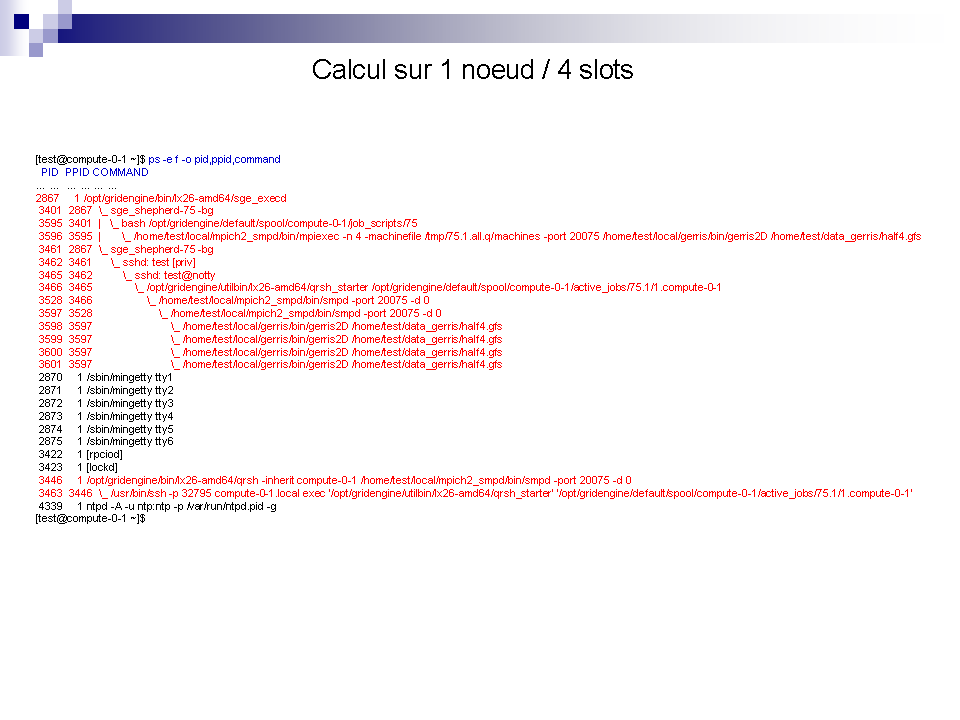
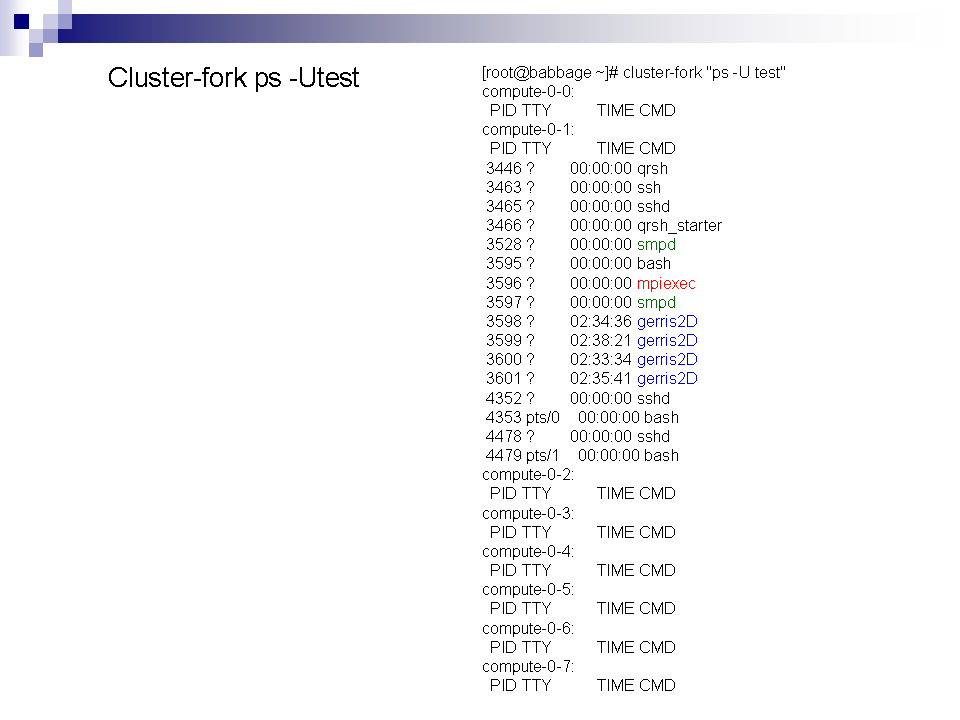
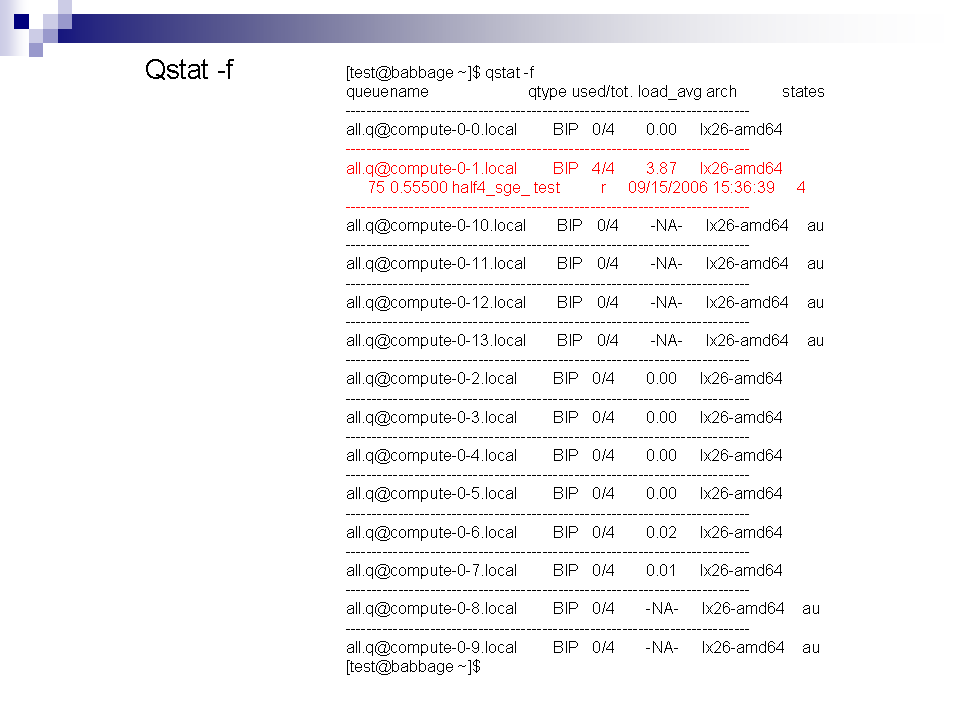
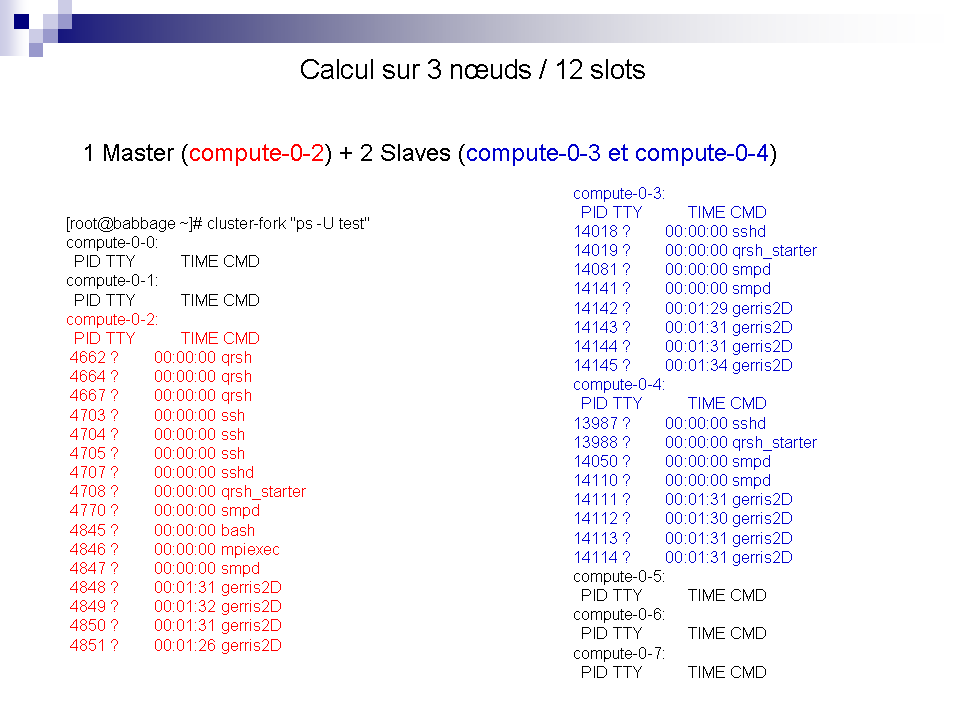
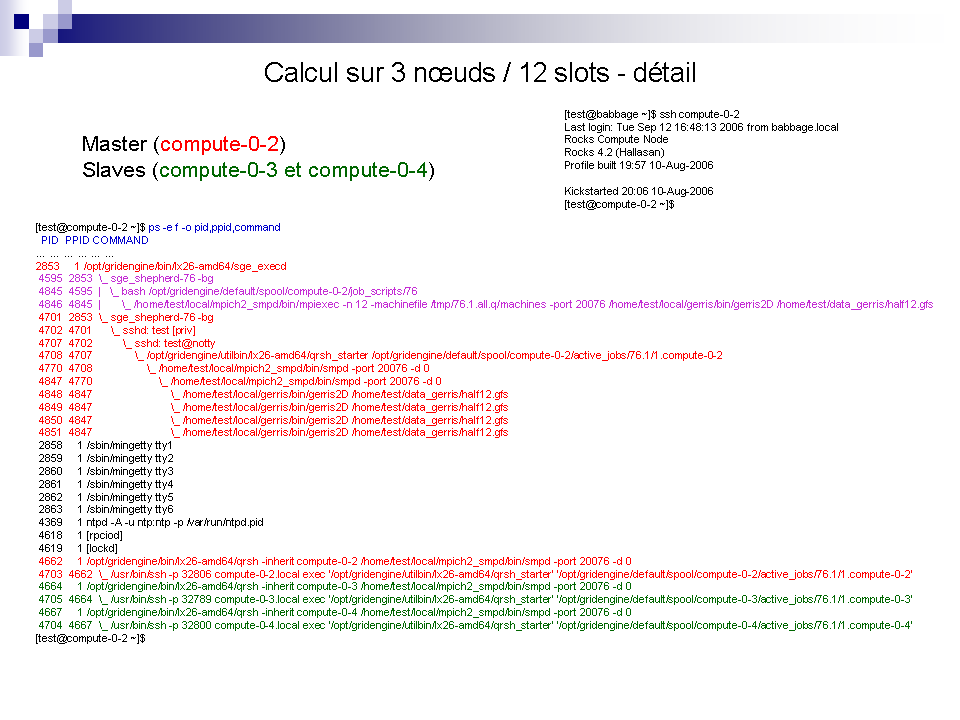

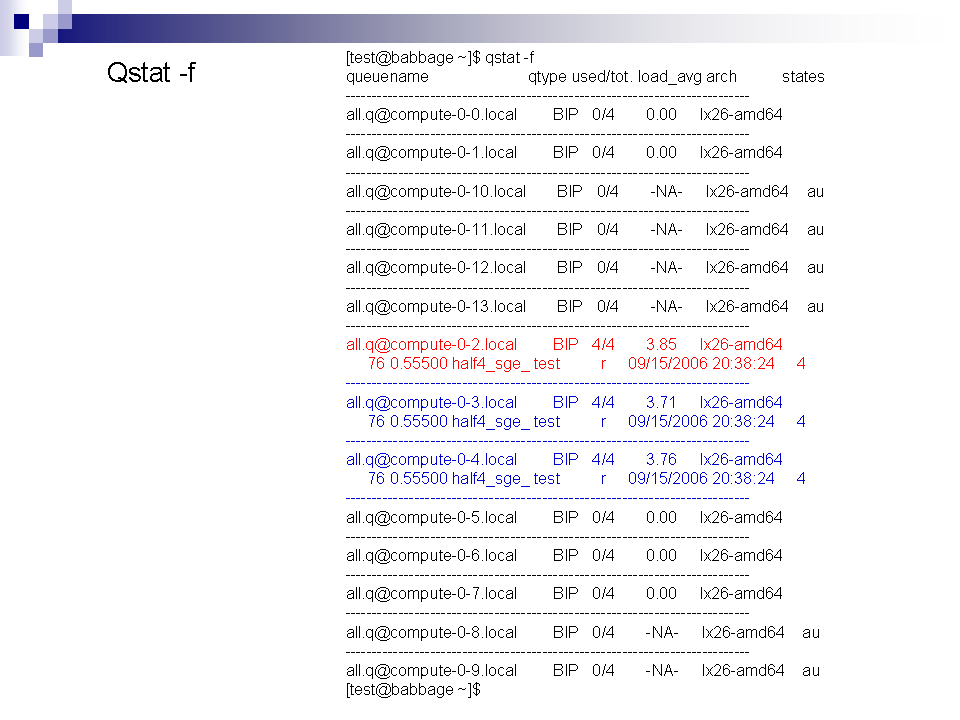
Où stocker mes données ?
Le frontal du cluster Babbage dispose de deux partitions en Raid 5, la première /home sur laquelle vous travaillez par défaut et qui est montée en NFS sur les noeuds, la deuxième /data pour
le stockage temporaire des données afin de libérer de la place sur le
/home et sur laquelle vous êtres libre de créer des répertoires. Pour
le stockage à plus long terme ou pour le traitement de vos données vous
devez utiliser la machine Tycho selon la procédure suivante :
Le
réseau actuel de l'Institut en 100 Mbs est trop lent pour transférer de
gros volumes de données, vos données sont donc automatiquement
transféré chaque nuit sur tycho via un lien local gigabit :
-babbage: /home est transféré sur tycho:/data0/home
-babbage:/data est transféré sur tycho:/data1/data
Vous
n'avez donc pas à les transférer, vous vous connectez simplement sur
tycho dans votre repertoire home qui est vide par
défaut, vous récupérez ce qui vous intéresse pour le
traiter en le copiant depuis /data0/home ou /data1/data vers
votre répertoire home. Vous pouvez ensuite supprimer ces données sur le frontal babbage, par synchronisation des répertoires les données seront aussi supprimées dans les répertoires /data0/home et /data1/data
la nuit suivante, mais les données que vous aurez mises sur votre home
tycho, elles, seront conservées. A cause des volumes de données il est
important de traiter vos données au fur et à mesure car il n'est pas
possible de tout conserver indéfiniment !